
OpenAI vừa công bố một liên minh hạ tầng với AMD, NVIDIA, Intel, Microsoft và Broadcom để giải bài toán giữ cụm GPU khổng lồ hoạt động đều khi huấn luyện AI. Theo bài viết kỹ thuật từ OpenAI, lời giải là giao thức MRC, cho phép một lần truyền dữ liệu đi qua nhiều đường song song thay vì bám vào một lộ trình cố định. Cách làm này xử lý hai điểm nghẽn lớn nhất của huấn luyện AI: tắc mạng và lỗi kết nối. Khi một gói tin đến trễ có thể làm cả cụm GPU phải chờ, OpenAI cho thấy huấn luyện AI quy mô lớn giờ là câu chuyện của mạng, không chỉ của chip.
Vì sao OpenAI phải kéo cả hệ sinh thái bán dẫn vào cùng một giao thức mạng?
Giao thức MRC được thiết kế cho những cụm huấn luyện đã lên tới hàng chục nghìn GPU. Thay vì coi một giao diện 800Gb/s là một đường duy nhất, OpenAI tách nó thành nhiều nhánh nhỏ hơn, như 8 nhánh 100Gb/s đi qua 8 switch khác nhau. Nhờ vậy, mạng hai tầng có thể kết nối khoảng 131.000 GPU, trong khi thiết kế Ethernet quen thuộc thường phải lên ba hoặc bốn tầng switch.
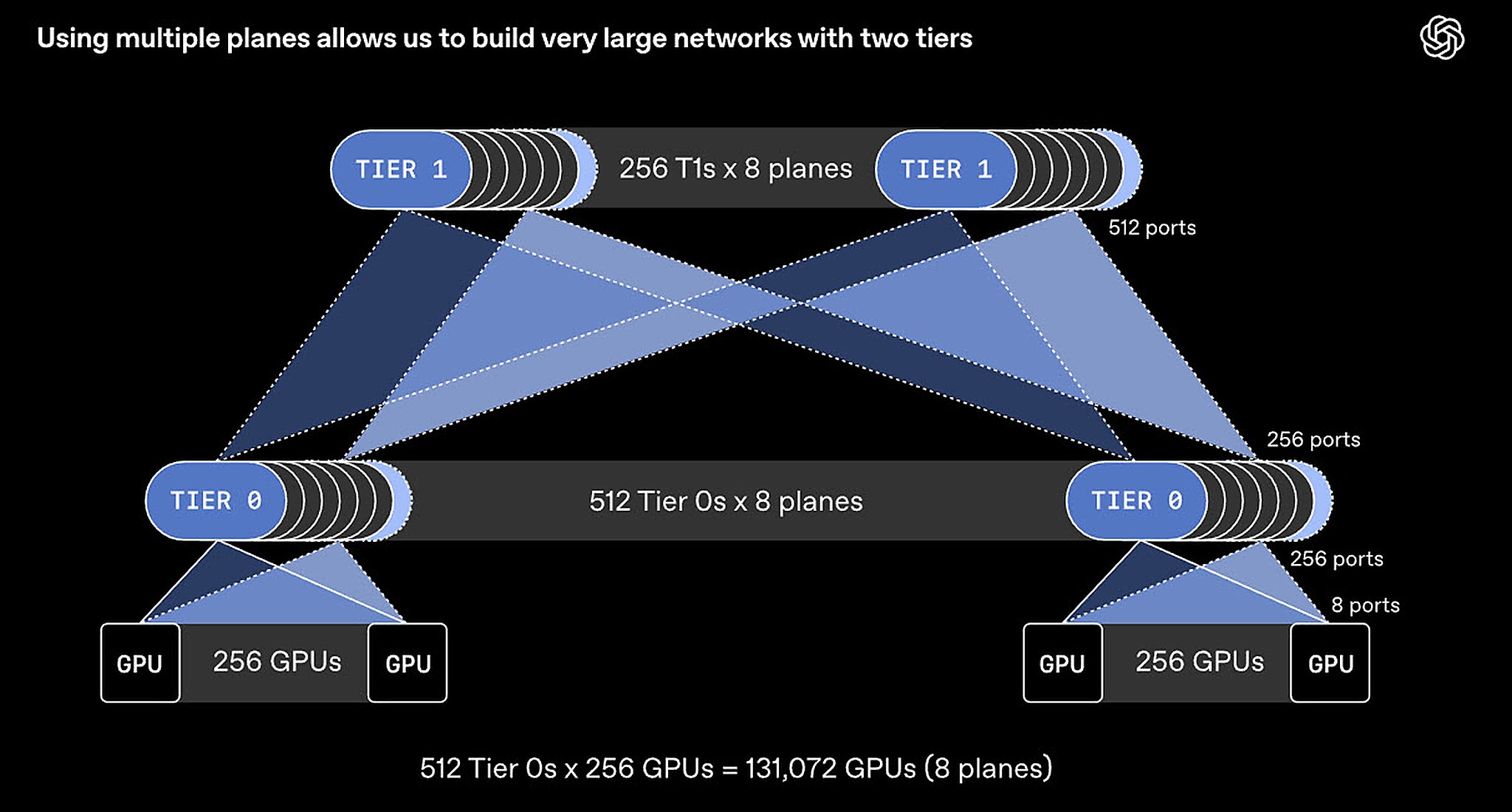
Điểm quan trọng hơn nằm ở cách MRC gửi dữ liệu. Thay vì ép cả phiên truyền đi một đường cố định để giữ đúng thứ tự, MRC rải gói tin qua hàng trăm đường khác nhau, tự tránh điểm nghẽn và loại bỏ tuyến gặp lỗi chỉ trong vài micro-giây. Với huấn luyện đồng bộ, nơi rất nhiều GPU phải chờ nhau ở từng bước, khác biệt này tác động trực tiếp đến hiệu suất thực tế: GPU bớt ngồi chờ, thời gian huấn luyện ngắn hơn và điện năng bị lãng phí cũng giảm theo.
OpenAI cho biết giao thức MRC đã chạy trên các siêu máy tính dùng NVIDIA GB200 để huấn luyện model frontier, gồm cụm Abilene tại Texas và các hệ thống Fairwater của Microsoft. Điều đó nối khá sát với bài OpenAI 30GW trên Technology Spot: khi tham vọng compute đi lên cấp độ gigawatt, mạng nội bộ trở thành giới hạn tăng trưởng thật sự.
Việc AMD, Broadcom, Intel, Microsoft và NVIDIA cùng góp mặt vì thế không chỉ mang ý nghĩa biểu tượng. NVIDIA và AMD đứng ở phía phần cứng tăng tốc; Broadcom và Intel có vai trò ở lớp kết nối; còn Microsoft là bên đưa giao thức này vào môi trường đám mây quy mô lớn. Khi chuẩn được đưa lên Open Compute Project theo hướng mở, khả năng tương thích giữa các lớp phần cứng trong tương lai cũng rộng hơn.
Ai được lợi khi cụm GPU có thể mở rộng nhanh hơn và ít lãng phí hơn?
Lợi ích đầu tiên thuộc về OpenAI và các hãng đang chạy mô hình lớn, vì mỗi phần trăm GPU bớt nhàn rỗi đều quy ra tiền, điện và thời gian phát triển. Nếu hạ tầng có thể giữ hơn 100.000 GPU chạy ổn định chỉ với mạng hai tầng, chi phí mở rộng cụm huấn luyện sẽ nhẹ hơn. Đó cũng là lý do OpenAI huấn luyện AI quy mô lớn đang dần trở thành bài toán của toàn bộ chuỗi cung ứng AI.
| Đối tác | Vai trò | Tác động dễ hiểu |
|---|---|---|
| OpenAI | Thiết kế MRC, đưa chuẩn lên OCP | Biến nhu cầu nội bộ thành chuẩn có thể dùng rộng hơn. |
| NVIDIA, AMD | GPU và giao diện mạng tốc độ cao | Giúp cụm tăng tốc tận dụng băng thông tốt hơn. |
| Broadcom, Intel | Thành phần mạng và kết nối | Giảm nghẽn và tăng độ bền ở quy mô lớn. |
| Microsoft | Triển khai trong siêu máy tính và cloud | Đưa giao thức từ tài liệu sang vận hành thật. |
Nhóm hưởng lợi tiếp theo là các nhà cung cấp hạ tầng AI khác. Khi giao thức MRC được mở ra cho cộng đồng, họ có thêm một hướng đi rõ ràng để giảm tắc nghẽn mạng. Đặt cạnh bài Intel TPU, có thể thấy cuộc đua AI đang dịch rất nhanh từ chuyện chip nào mạnh hơn sang chuyện ai ghép được chip, mạng và data center thành một hệ thống ít lãng phí hơn.
Với người dùng cuối, tác động sẽ đến gián tiếp nhưng không nhỏ. Hạ tầng ổn định hơn có thể rút ngắn thời gian huấn luyện, và giao thức MRC có thể chưa phải cái tên quen thuộc như GPU Blackwell hay Stargate. Tuy vậy, đây là loại công nghệ quyết định AI lớn được xây nhanh đến đâu.
4 bình luận về “OpenAI bắt tay AMD, NVIDIA, Intel, Broadcom tăng tốc AI”