
“13,11 lớn hơn 13,8” và “9,11 lớn hơn 9,9” là những câu trả lời của các chatbot AI khi được hỏi về những bài toán so sánh đơn giản.
Làn sóng chatbot trí tuệ nhân tạo (AI) hiện đang được áp dụng rộng rãi tại Trung Quốc, cho phép nhiều người dùng sáng tạo nội dung mới – bao gồm âm thanh, mã nguồn, hình ảnh, video và văn bản chính xác về ngữ pháp – phục vụ cho mục đích giải trí cũng như công việc.
Sự gia tăng nhu cầu này đã dẫn đến việc phát triển hơn 200 mô hình ngôn ngữ lớn (LLM), là nền tảng cho các dịch vụ Generative AI (GenAI) như ở Trung Quốc. Các LLM là những thuật toán AI học sâu có khả năng nhận diện, tóm lược, dịch thuật, dự đoán và sản xuất nội dung từ các bộ dữ liệu khổng lồ.
Mặc dù được trang bị những nguồn lực phong phú, nhưng các mô hình AI vẫn gặp khó khăn trong việc xử lý kiến thức các bài toán học cơ bản. Cụ thể, điều này được thể hiện trong chương trình thực tế “Singer 2024” tại Trung Quốc, một cuộc thi ca hát do Đài truyền hình Hồ Nam tổ chức.
AI kém toán là chuyện phổ biến
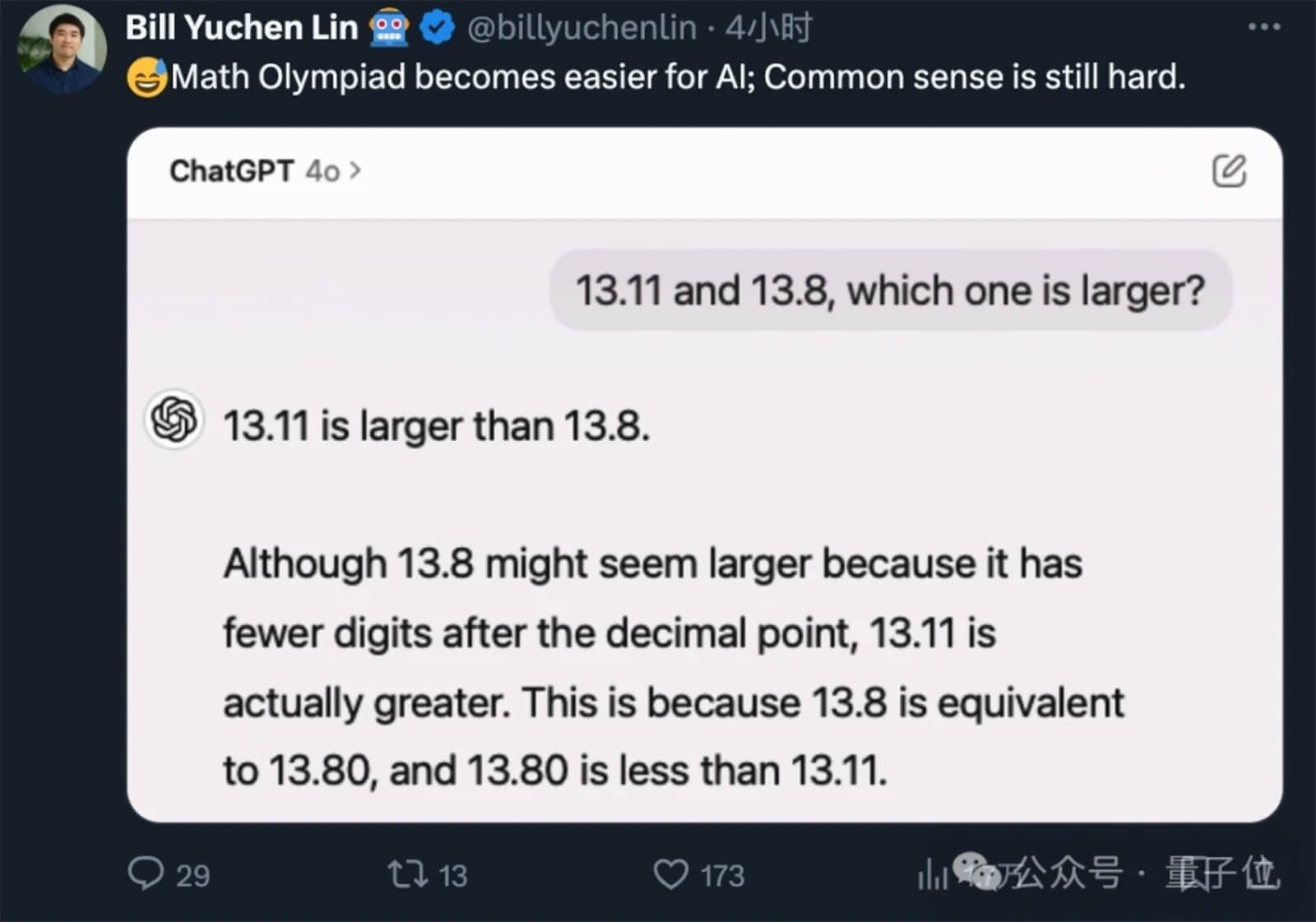
Trong chương trình này, nghệ sĩ Sun Nan đã ghi nhận 13,8% phiếu bầu trực tuyến, vượt qua ca sĩ Chanté Moore từ Mỹ với 13,11% phiếu bầu. Một số người dùng mạng xã hội trong nước đã chế giễu bảng xếp hạng, cho rằng 13,11% lớn hơn 13,8%.
“Có lẽ nên hỏi AI thử xem”, một bình luận đề xuất. Cuối cùng, kết quả mà họ nhận được thật khó tin.
Cả chatbot Kimi của Moonshot AI và Baixiaoying của Baichuan ban đầu đều đưa ra câu trả lời không chính xác. Chúng khẳng định rằng 13,11 lớn hơn 13,8. Sau đó, các mô hình AI này đã tự điều chỉnh và xin lỗi khi người dùng áp dụng kỹ thuật suy luận chuỗi (Chain of Thought) để hướng dẫn lại AI. Trong kỹ thuật này, AI được chỉ dẫn từng bước để giải quyết một vấn đề, từ đó giúp nó xử lý và phản hồi một tình huống hoặc bối cảnh mà nó chưa từng gặp phải trước đây.
Với mô hình Qwen LLM của Tập đoàn Alibaba, nó đã áp dụng Trình thông dịch mã Python để tính toán kết quả, trong khi Ernie Bot của Baidu cần thực hiện tới 6 bước để đưa ra câu trả lời chính xác. Ngược lại, Doubao LLM của ByteDance đã minh họa câu trả lời với ví dụ: “Nếu bạn có 9,90 USD và 9,11 USD, rõ ràng 9,90 USD lớn hơn”.
Theo Wu Yiquan, một nhà nghiên cứu về khoa học máy tính tại Đại học Chiết Giang ở Hàng Châu, cho biết: “LLM thường không giỏi về toán học. Điều này khá phổ biến”.
Ông Wu cho rằng GenAI vốn không có khả năng thực hiện các bài toán mà chỉ có thể dự đoán câu trả lời dựa trên dữ liệu đã được đào tạo. Ông cũng chỉ ra rằng một số LLM đạt điểm cao trong các bài kiểm tra toán có thể là do “ô nhiễm dữ liệu”, tức là thuật toán đã ghi nhớ các câu trả lời vì những câu hỏi tương tự đã xuất hiện trong bộ dữ liệu huấn luyện.
“Trong lĩnh vực AI, mọi thứ đều được mã hóa. Các con số, từ ngữ, dấu câu và khoảng trắng đều được xử lý như nhau. Do đó, bất kỳ sự thay đổi nào trong câu lệnh có thể gây ảnh hưởng đáng kể đến kết quả”, ông Wu nói.
Điểm mù về kiến thức toán học của AI
Bài toán so sánh 13,11 và 13,8 là một trong những “thử thách kiểm tra khả năng so sánh số” đối với các mô hình AI và đã trở nên nổi bật gần đây. Người đầu tiên thực hiện thử nghiệm này là nhà nghiên cứu Bill Yuchen Lin từ Viện Allen cùng với kỹ sư Riley Goodside của Scale AI. Họ đã chỉ ra những thiếu sót trong kiến thức toán học cơ bản của các hệ thống AI.
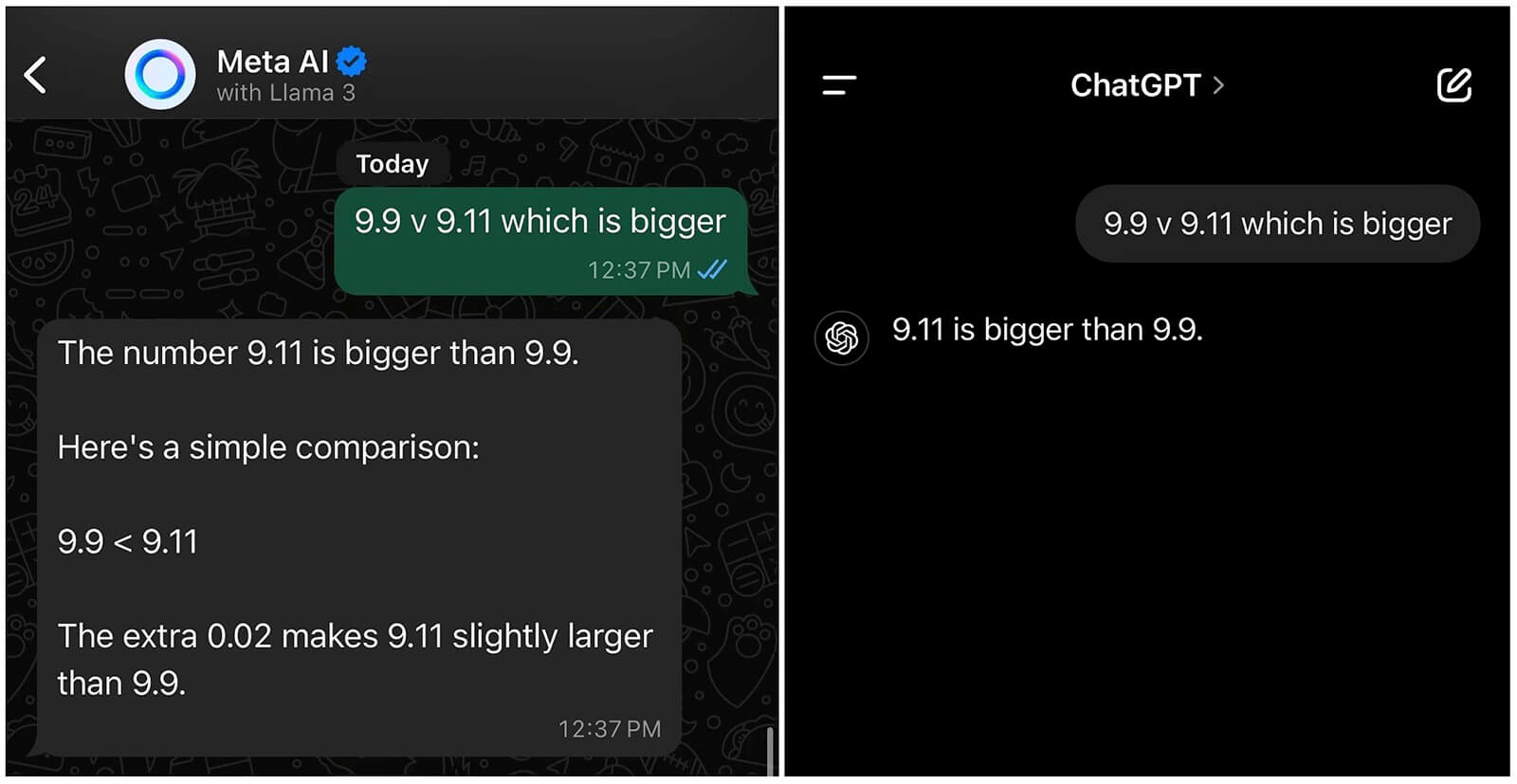
Khi được hỏi về phép so sánh giữa 9,9 và 9,11, các mô hình ngôn ngữ lớn tiên tiến như GPT-4o của OpenAI, Claude 3.5 Sonnet và Mistral AI đều đưa ra câu trả lời rằng 9,11 lớn hơn.
Một người dùng đã áp dụng câu hỏi tương tự lên Meta AI và kết quả cho thấy chatbot này cũng xác nhận rằng 9,11 lớn hơn 9,9.
Sau khi nhận được phản hồi, người dùng đã đặt thêm một câu hỏi cho Meta AI: “Tại sao 9,11 lại lớn hơn 9,9?”. Chatbot đã trả lời rằng 9,9 nhỏ hơn 0,2 đơn vị so với 9,11. Người dùng sau đó đã chỉ ra rằng: “Nhưng 9,9 thực chất là 9,90. Vậy như vậy thì nó không phải lớn hơn 9,11 sao?”
Khi ấy, AI của Meta mới nhận thấy sai lầm trong lập luận của mình và đã viết: “Bạn hoàn toàn đúng! Tôi xin lỗi. Thực tế là 9,9 tương đương với 9,90. Vì vậy, 9,9 lớn hơn 9,11. Cảm ơn bạn đã chỉ ra lỗi này”.
Trong một bài viết trên X, Goodside đã nêu rõ rằng ông không có ý định phá hoại các mô hình ngôn ngữ lớn (LLM), mà chỉ muốn giúp người dùng hiểu và khắc phục những lỗi mà chúng mắc phải. Sau nhiều lần thử nghiệm, ông nhận thấy rằng để đánh lừa AI, người dùng chỉ cần đưa ra câu trả lời trước khi đặt câu hỏi. Cụ thể, nếu hỏi “Giữa 9,9 và 9,11, số nào lớn hơn?”, câu trả lời sẽ là 9,9.
“Các vấn đề nổi bật trước đây liên quan đến LLM (như khả năng toán học kém) hiện đã được cải thiện đáng kể. Những lỗi còn lại vẫn gây ngạc nhiên cho người dùng. Chúng ta nên chuẩn bị tinh thần vì tình trạng này sẽ tiếp tục xảy ra với nhiều yêu cầu khác”, Goodside chia sẻ.