
DeepSeek V4 KV cache là chi tiết đáng chú ý nhất trong lần ra mắt này: ở ngữ cảnh 1 triệu token, bản Pro được công bố chỉ còn cần 10% bộ nhớ KV cache so với DeepSeek V3.2. KV cache có thể hiểu là phần bộ nhớ giúp mô hình giữ lại những gì vừa đọc để token tiếp theo không phải tính lại toàn bộ lịch sử. Với các tác vụ dài như đọc log, rà tài liệu lớn hay chạy agent qua nhiều bước, đây thường là điểm khiến chi phí suy luận tăng rất nhanh. Vì vậy, việc cắt mạnh phần bộ nhớ này cho thấy ngữ cảnh siêu dài đang tiến gần hơn tới mức có thể triển khai thực tế, chứ không chỉ là thông số để trưng bày.
Vì sao giảm KV cache lại đáng chú ý với mô hình 1 triệu token?
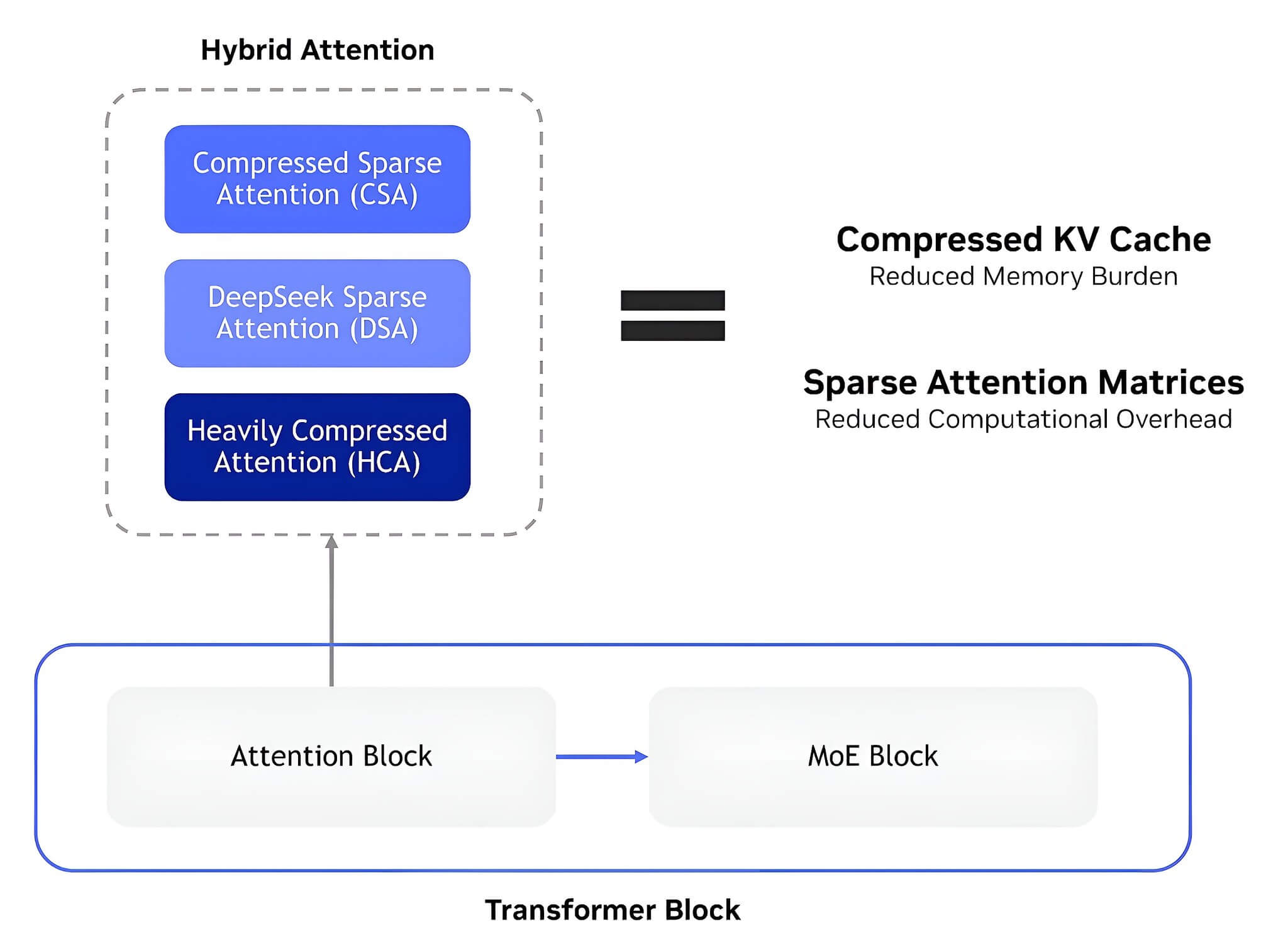
Khi một mô hình phải giữ hàng trăm nghìn đến cả triệu token trong đầu, vấn đề không còn là “có hỗ trợ context dài hay không” mà là có đủ bộ nhớ để chạy ổn định hay không. KV cache giống như chồng ghi chú tạm mà mô hình liên tục tra lại trong lúc sinh câu trả lời; chồng ghi chú ấy càng dày, mỗi token mới càng tốn bộ nhớ và độ trễ.
Trong technical report DeepSeek, DeepSeek cho biết ở mốc 1 triệu token, bản Pro chỉ còn cần 27% FLOPs cho suy luận từng token và 10% KV cache so với V3.2; bản Flash còn hạ xuống 10% FLOPs và 7% KV cache. Nói ngắn gọn, DeepSeek V4 KV cache nhỏ đi nhờ attention được nén và chọn lọc lại ngay từ kiến trúc lõi.
Ý nghĩa thực tế nằm ở kinh tế triển khai. Khi một phiên suy luận chiếm ít bộ nhớ hơn, nhà cung cấp có thể tăng số phiên chạy đồng thời trên cùng cụm GPU hoặc giảm áp lực phần cứng cho các bài toán ngữ cảnh dài. Trong lúc cả ngành vẫn phải cân đo từng watt điện cho hạ tầng AI, giảm gánh nặng bộ nhớ gần như đồng nghĩa với hạ chi phí vận hành.
NVIDIA cũng nhìn V4 theo hướng đó: model này phù hợp hơn cho coding dài, phân tích tài liệu lớn và agent nhiều bước, tức những kịch bản mà context window rộng chỉ thực sự có ích khi bộ nhớ không đội lên quá nhanh.
Hiệu quả cao hơn, nhưng độ chính xác truy hồi có thể phải trả giá
Đổi lại, nén mạnh bộ nhớ luôn kéo theo một câu hỏi khó: mô hình còn giữ đủ chi tiết hay không. DeepSeek cho biết V4 kết hợp nhiều nhánh attention với mức nén khác nhau để vừa giữ chi phí thấp vừa không đánh mất hoàn toàn thông tin cũ. Nhưng về bản chất, càng nén mạnh thì rủi ro bỏ sót một chi tiết hiếm nằm rất sâu trong ngữ cảnh càng lớn.
| Phần được tối ưu | Lợi ích dễ thấy | Rủi ro đi kèm |
|---|---|---|
| KV cache nhỏ hơn | Giảm bộ nhớ cho mỗi phiên suy luận dài | Chi tiết nhỏ có thể khó giữ nguyên |
| Nén attention theo lớp | Hạ FLOPs khi lịch sử rất dài | Truy hồi chi tiết ở cuối ngữ cảnh có thể kém ổn định |
| Context 1 triệu token | Hợp hơn cho agent, log và kho tài liệu lớn | Không đồng nghĩa mọi chi tiết trong 1M token đều được lấy lại chính xác |
Đó là lý do các bài test kiểu “needle in a haystack” vẫn rất quan trọng. Trong báo cáo, DeepSeek dùng bài MRCR để đo truy hồi theo chiều dài ngữ cảnh và thừa nhận hiệu năng bắt đầu giảm rõ sau mốc 128K token. Ở 1M token, DeepSeek V4 Pro Max đạt 83,5 điểm trên MRCR, vẫn vượt Gemini 3.1 Pro nhưng còn cách Claude Opus 4.6 ở mức 92,9.
Với các đội ngũ đang cân nhắc triển khai agent dài hơi, thay đổi của DeepSeek đáng chú ý vì nó chạm thẳng vào chi phí phần cứng, thay vì chỉ làm đẹp bảng benchmark.
Điều này không phủ nhận lợi ích của DeepSeek V4 KV cache nhỏ hơn. Nó chỉ nhắc rằng context 1 triệu token không phải tấm vé miễn kiểm thử: chatbot tổng hợp tài liệu hay agent theo dõi lịch sử dài sẽ hưởng lợi rõ, nhưng các hệ thống phải tìm đúng một dòng hợp đồng, một lỗi log hiếm hay một chi tiết nhỏ trong kho mã vẫn cần test retrieval riêng trước khi đưa vào vận hành. anthropic vượt openai




0 phản hồi cho “DeepSeek giảm 90% KV cache ở 1 triệu token: lợi và hại là gì?”