Nếu mọi người đang chờ một mô hình AI mã nguồn mở đủ nhẹ để chạy local nhưng vẫn có reasoning, coding và agent workflow tử tế, Gemma 4 đang trở thành cái tên đáng chú ý hơn nhiều sau màn bắt tay mới giữa Google và NVIDIA. Theo thông tin công bố ngày 2/4/2026, Gemma 4 hiện đã được tối ưu để chạy trên dải phần cứng NVIDIA từ PC dùng GPU GeForce RTX đến DGX Spark và cả thiết bị edge. Điểm đáng chú ý nhất là RTX 5090 cho tốc độ suy luận với Gemma-4-31B nhanh hơn tới 2,7 lần so với Apple M3 Ultra trong bài đo llama.cpp. Với nhóm người dùng muốn dựng AI agent ngay trên máy cá nhân thay vì phụ thuộc hoàn toàn vào cloud, đây là bước tiến có ý nghĩa thực tế hơn nhiều so với một màn phô diễn benchmark đơn thuần.
Thông tin từ Google Gemma 4 cho thấy dòng model này được xây theo hướng nhỏ gọn, chạy được trên nhiều lớp phần cứng và hỗ trợ đa nhiệm vụ thay vì chỉ tập trung vào chatbot văn bản. Bốn biến thể hiện tại gồm E2B, E4B, 26B và 31B, trải từ nhóm model edge siêu nhẹ đến nhóm model lớn hơn dành cho suy luận và coding. Đây cũng là lý do Gemma 4 đang được nhắc tới nhiều trong bối cảnh AI local tăng tốc, vì người dùng không cần datacenter vẫn có thể triển khai workload ngay trên desktop hoặc workstation.
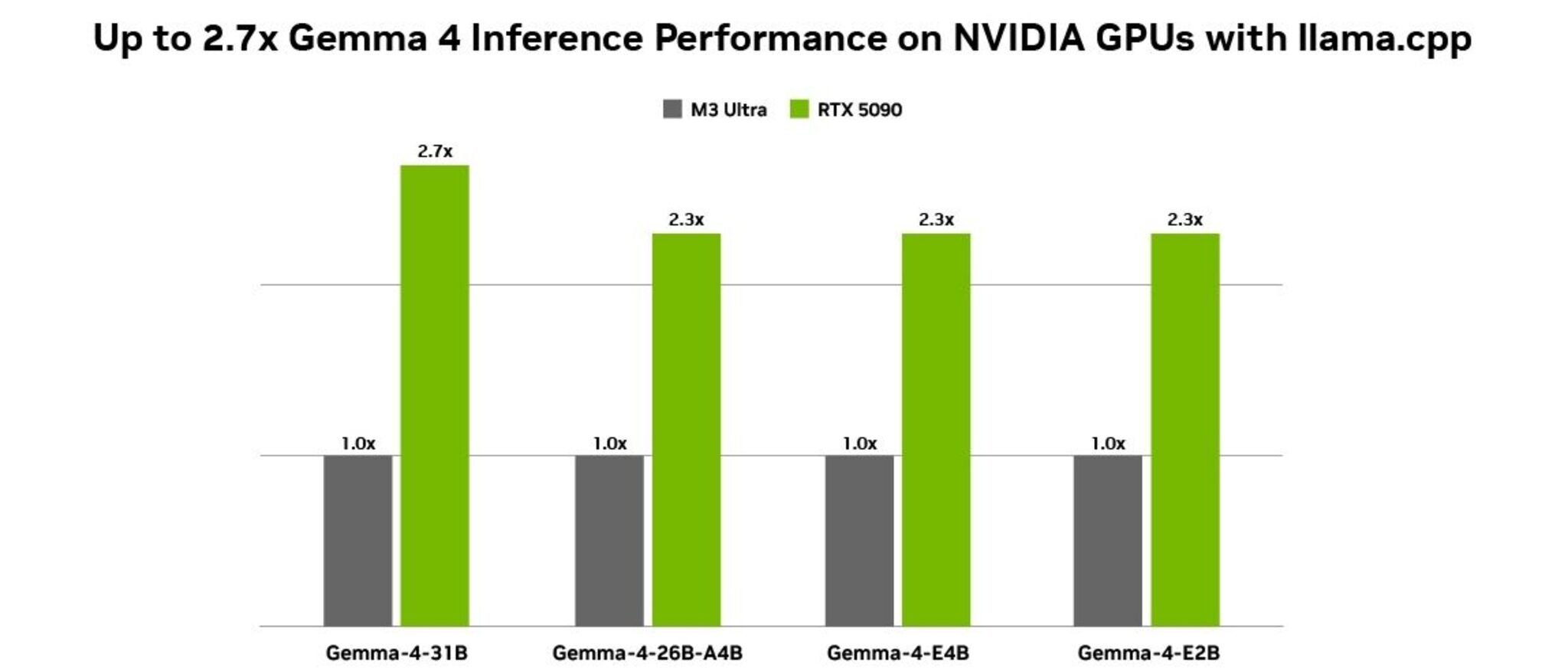
Gemma 4 nhanh hơn trên NVIDIA RTX ở điểm nào?
Theo bài viết gốc và dữ liệu NVIDIA công bố, Gemma 4 được tối ưu để chạy hiệu quả trên phần cứng NVIDIA từ GPU RTX trong PC cá nhân đến DGX Spark và Jetson Orin Nano. Bài đo được thực hiện với llama.cpp, dùng quantization Q4_K_M, batch size 1, input sequence length 4096 và output sequence length 128. Ở cấu hình Gemma-4-31B, RTX 5090 đạt tốc độ cao hơn 2,7 lần so với M3 Ultra, còn với model nhỏ hơn mức chênh lệch vẫn vào khoảng 2,3 lần. Đây là khác biệt đủ lớn để tác động trực tiếp đến trải nghiệm thực tế, nhất là khi người dùng cần phản hồi nhanh trong coding assistant hoặc agent xử lý nhiều bước liên tiếp.

Điểm hay của Gemma 4 không nằm ở một con số benchmark duy nhất mà ở phạm vi tác vụ nó hỗ trợ. Google cho biết model này có reasoning, coding, function calling cho agent, hiểu đầu vào đa phương thức như văn bản và hình ảnh, đồng thời hỗ trợ hơn 35 ngôn ngữ ngay từ đầu. Với nhóm phát triển sản phẩm AI, điều đó có nghĩa Gemma 4 không chỉ dùng để chat mà còn có thể đóng vai trò lõi cho bot hỗ trợ lập trình, công cụ phân tích tài liệu, pipeline nhận diện hình ảnh hoặc tác vụ tự động hóa nội bộ. Nếu kết hợp với hệ sinh thái NVIDIA, mô hình này đang có cơ hội trở thành một lựa chọn thực dụng cho làn sóng AI chạy ngay trên máy cá nhân.
Hai biến thể E2B và E4B được nhấn mạnh ở khả năng chạy offline với độ trễ gần như bằng 0 trên thiết bị edge, trong khi 26B và 31B phù hợp hơn cho workflow agentic AI và coding assistant. Người làm embedded AI có thể quan tâm tới E2B và E4B vì ưu tiên phản hồi nhanh, còn nhóm lập trình viên hoặc doanh nghiệp nhỏ muốn chạy agent local sẽ nhìn sang 26B và 31B.
Gemma 4 mở ra gì cho AI local trên PC và workstation?
NVIDIA cho biết Gemma 4 hiện có thể triển khai local qua Ollama hoặc llama.cpp kết hợp checkpoint GGUF từ Hugging Face. Về mặt thực tiễn, điều này làm giảm đáng kể rào cản tiếp cận vì đây đều là công cụ quen thuộc với cộng đồng đang thử nghiệm LLM trên máy cá nhân. Chi tiết thêm về hướng triển khai và tối ưu được NVIDIA chia sẻ trên NVIDIA Blog, cho thấy hãng đang đẩy khá mạnh chiến lược biến RTX PC thành nền tảng AI local thực thụ.
Ý nghĩa lớn hơn nằm ở chỗ Gemma 4 đang thu hẹp khoảng cách giữa AI tiêu dùng và AI chuyên dụng. Khi một model 31B có thể khai thác tốt Tensor Core trên GPU desktop, người dùng cá nhân hoặc studio nhỏ không còn phải chọn giữa hiệu năng và quyền kiểm soát dữ liệu. Chạy local giúp xử lý tài liệu riêng tư ngay trên máy, giảm phụ thuộc vào cloud và giữ độ trễ ổn định hơn trong các tác vụ cần phản hồi liên tục. Với thị trường workstation, đây là tín hiệu quan trọng vì GPU giờ không chỉ phục vụ dựng hình hay gaming mà còn trở thành phần cứng cốt lõi cho một lớp phần mềm AI mới.
Dù vậy, Gemma 4 chưa phải lời giải cho mọi kịch bản. Model nhỏ như E2B hay E4B sẽ hợp với edge AI và tác vụ đơn giản hơn, còn 26B và 31B vẫn cần phần cứng đủ khỏe nếu muốn khai thác trọn vẹn. Trong ngắn hạn, đây là bước đi có lợi cho cả Google lẫn NVIDIA — một bên mở rộng sức ảnh hưởng của Gemma 4, bên còn lại chứng minh rằng GPU RTX đang có chỗ đứng rõ ràng trong làn sóng AI local đang tăng nhiệt rất nhanh.
Nguồn: WCCFTech




0 phản hồi cho “Google Gemma 4 chạy trên GPU NVIDIA RTX, nhanh hơn 2,7 lần so với M3 Ultra”